
笔记作者:CDra90n
原文作者:Qiuyuan Chen, Lingfeng Bao, Li Li, Xin Xia, Liang Cai
原文标题:Categorizing and Predicting Invalid Vulnerabilities on Common Vulnerabilities and Exposures
原文来源:2018 25th Asia-Pacific Software Engineering Conference (APSEC)
原文地址:https://www.researchgate.net/publication/333348790_Categorizing_and_Predicting_Invalid_Vulnerabilities_on_Common_Vulnerabilities_and_Exposures
0x00 摘要
为了在独立的数据库,工具和服务之间共享漏洞信息,新发现的漏洞会定期报告给“公共漏洞和暴露(CVE, Common Vulnerabilities and Exposures)”数据库。不幸的是,并非所有漏洞报告都将被接受。他们中的一些人可能会被拒绝或因争议而被接受。在这项工作中将那些被拒绝或有争议的CVE称为无效漏洞报告(Invalid Vulnerabilitie)。无效的漏洞报告不仅会导致不必要的努力来确认漏洞,还会影响软件供应商的声誉。
本文旨在了解无效漏洞报告的根本原因,并建立一个预测模型以自动识别它们。为此,首先利用卡片分类法对无效漏洞报告进行分类,从中可以分别观察到CVE被拒绝和存在争议的六个主要原因。然后提出一种文本挖掘方法来预测无效漏洞报告。实验表明,所提出的文本挖掘方法可以在预测无效漏洞方面获得0.87的AUC评分。
研究的意义:分类可以用来指导新提交者避免这些陷阱。可以通过使用自动技术或优化检查机制来避免无效CVE的某些根本原因;不应忽略无效漏洞报告数据。
0x01 简介
软件漏洞是软件系统中的可利用漏洞,会对主机计算系统造成重大安全风险。用户经常遭受软件漏洞的困扰,因为软件不可避免地要面对这些漏洞。发现和验证漏洞后,就会记录漏洞并通过漏洞数据库向公众公开。最具影响力的漏洞数据库之一是CVE,它旨在允许将不同的漏洞数据库和其他功能链接在一起。 CVE为给定漏洞提供了标准化的标识符,并维护了众多已知公共网络安全漏洞的常用标识符。尽管CVE是数据库,为方便起见,它也经常用于漏洞报告的引用(即,每个漏洞报告都是CVE或CVE条目)。
在这项工作中关注于无效漏洞报告(即被拒绝的CVE或引起争议随后被接受的CVE),这些报告通常以低质量的描述提交,并且相应的漏洞不能如报告所述,不易于验证,不可复现或不能真正影响安全。对无效漏洞报告感兴趣的原因是,这些报告可能给CVE的生态系统带来很多麻烦。实际上,在提交漏洞报告时,需要分配一定数量的专业人员来验证漏洞。如果事实证明该漏洞是无效案例,则实际上是在浪费很多精力来确认此无效性。更糟糕的是,可能由于缺乏足够的描述来再现漏洞而拒绝了CVE,而这些漏洞实际上是有效漏洞。
这些无效CVE(由于其被判定无效而不会修补)实际上将为攻击者打开利用它们的机会。而且,尽管无效的CVE可能不会真正给软件带来安全威胁,但仍可能影响软件的声誉。由于CVE通常仅具有有限的信息,因此,诉诸美国国家漏洞数据库(NVD)来进一步收集(尽可能)在对CVE进行审查时附加的注释。将收集数据记录中所有自2002年以来直到2017年底的NVD数据。此步骤生成99,934个独立的CVE条目,与至少378个供应商和444个软件产品相关联。在99,934个CVE中,其中5,442个(约5%)被标记为无效(例如,通过授权机构附有的标签“ REJECTED”和“ DISPUTED”)。
在本文中,基于收集的无效CVE进行了手动探索性研究,以了解其被标记为无效的原因。利用卡片分类方法对拒绝和有争议的CVE进行分类,最终分别得到拒绝和争议CVE的六个原因。拒绝CVE的主要原因是由于重复或无法复现,而引起争议的CVE的主要原因是它们无法复现。
在观察与无效CVE相关的根本原因之后,这项工作中进行了更深一步来自动预测新提交的CVE是否将被标记为无效。因此建立了一个机器学习模型,可以从整个无效CVE数据集中学习。机器学习模型采用了几种经典的分类算法,包括朴素贝叶斯,多项式朴素贝叶斯,支持向量机和随机森林。
使用AUC来评估研究中所提出的预测模型的性能,因为AUC是独立于阈值的量度,具有清晰的统计解释,并且对数据分布不敏感。通过10倍交叉验证和时间序列验证来评估这些分类器,即使用前五年的数据来预测未来五年内漏洞报告的有效性。实验结果表明机器学习模型对于预测CVE是否被拒绝非常有效。值得注意的是,随机森林分类器可实现最佳性能(超过0.8 AUC)。除了产生预测模型外,本研究还对寻找可有助于区分有效和无效CVE的特征感兴趣。因此还基于所有特征的信息增益得分来介绍最重要的特征。
这项研究的目的是更好地理解被提交的CVE是如何呈现的以及为什么变得无效。希望从回答这些问题中学到的见识可用于指导新提交者避免这些陷阱。本文的主要贡献如下:
1)对从已知CVE收集的无效漏洞报告进行了探索性研究。通过利用卡片分类方法的时效性,手动对导致获候选CVE被拒绝或引起争议的主要原因进行分类。
2)建立机器学习模型以自动预测新提交的CVE的有效性。实验结果表明,有希望自动预测CVE是否将变为无效。还将介绍可帮助区分有效和无效CVE的主要区分特征。
0x02 背景
在本节中,首先介绍如何生成CVE条目并将其转换为不同状态的机制,然后描述什么是无效CVE条目。
A. CVE的生命周期
上图展示了CVE条目的生命周期。一旦提交者在软件产品中发现漏洞,他们将向CVE编号颁发机构提交表单-CVE的颁发机构和管理者。然后,将在保留状态下检查此CVE条目。如果审阅者确认,它将被披露并向公众公开;如果它没有通过测试,它将被拒绝,可能有评论也可能没有。有时权威机构出于安全目会保留原始描述。披露CVE后,它将提醒公司和组织避免或修复此漏洞。
但是,如果实践表明此CVE条目不能按预期运行或者出现争议,则CVE将被发送回验证阶段。同时,CVE的状态将切换为“ DISPUTED”,并且也将向公众公开。然后,在重新检查后,它将被拒绝或标记为有效。拒绝的CVE可以重新检查,也可以转换回有效状态。在确定其有效或无效之前,争议状态是一个临时阶段,但是其中一些CVE被暂停了很长时间。
B.无效CVE
在研究中,无效的CVE条目指的是不合格的漏洞报告,并且如报告所声称的,其相应的漏洞不能被验证、重现或不能真正影响安全性。本文中无效CVE包括拒绝的CVE和有争议的CVE。拒绝的CVE将导致不必要的麻烦,例如浪费时间进行检查和修复。有争议的CVE将干扰披露,因为这些漏洞不能真正被视为威胁,并且也将导致供应商的恐慌和诽谤。

上图是从NVD中提取的无效CVE条目的示例。此CVE的索引显示在顶部,并按表示时间排序。标签“ REJECTED ”表示这是无效的CVE。条目注释用于判断CVE的有效性并给出其解释。原始描述介绍了该漏洞以及它的工作方式。其原始发布日期和上次修改日期也显示在右侧。
0x03 数据集
在本节中首先介绍收集CVE数据的步骤,然后重点介绍无效CVE数据,包括识别和预处理CVE报告以及相应的数据(即描述)以提取更多信息以供进一步研究。
A.数据收集
从NVD(CVE数据库的父集)收集所有数据,时间跨度为2002年至2017年。到2017年底,CVE条目数为99,934。这些漏洞在应用程序,操作系统和硬件类别中的36,436种产品中广泛发现。此外发现数据库搜索引擎无法检索到包含历史数据的废弃页面。只能通过使用特定CVE索引号的URL(例如CVE-2013-7030)进行访问。抓取了这些被拒绝CVE的页面,得到了历史信息,其中包括发布时间和修改时间等时间戳。在抓取的数据中,确定了5,442个无效的CVE条目。下表列出了有效和无效CVE的统计信息。
B.数据预处理
通过指定的标签 REJECT 和DISPUTED识别CVE中的无效记录,以便进一步进行调查。逐步挖掘这些原始数据,处理的每个步骤都会为特定目的生成数据。如上表所示,无效CVE条目最多占5%。但是由于技术和安全原因,在某些情况下CVE条目在被移出“RESERVED”状态之前被拒绝,并且原始详细信息也被丢弃。向CVE官方发送了电子邮件,但他们也没有将其保留在历史记录中,例如与保留状态关联的元数据被丢弃了。此外发现许多注释的注释如下:
这种CVE没有有用的信息来识别根本原因,因此也应丢弃。利用启发式规则以及手动检查来识别这些CVE。结果,大约80%的CVE被排除在工作之外。手动分析剩余的1,128个漏洞报告以进行特征研究。
C.数据分析
研究集中于无效(被拒绝和有争议的)CVE条目,对涉及无效CVE的人员感兴趣。 CVE只能被官方拒绝,而有争议的CVE中的情况却很复杂:供应商可以对CVE提出争议,因为供应商有责任检查收到的报告中的漏洞并及时提供反馈;第三方(例如Red Hat或Google Secure Team)也可能对此提出异议。有时,它也会由CVE机构本身报告。本文检查这些数据并在下表中列出这些争议的参与者。这些争议大多数由供应商提出,有时也由第三方提出。

下表显示了无效CVE影响的产品和供应商的数量和比例。由于有许多被拒绝的CVE条目在移出“RESERVED”状态之前尚未与供应商和产品建立联系,因此无法获得供应商名称和产品。对于这些无效的CVE,还发现Microsoft,Symantec和PHP是最常提及的供应商,而Windows和Norton Antivirus是最常提及的产品。
0x04 无效CVE分类的实证研究
为了更好地理解CVE无效的原因,基于提取的数据进行了实证研究。考虑到无效漏洞的影响及其产生方式,应用卡片分类法将CVE条目分类。卡片分类法广泛用于生成类别。在卡片分类法中,参与者创建类别名称并将条目分类。卡片分类过程分为两个阶段:
在准备阶段,为每个CVE条目创建一张卡。在执行阶段,卡片按照描述性标题分为有意义的组,由两组人工为卡片贴标签。对于每张卡,都突出显示了与根本原因相关的关键字,并将它们与具有相似关键字的卡分类为同一组。
然后为每个确定的类别分配了一个有意义的名称。使用Fleiss Kappa来衡量两组人工分类的一致性。总体Kappa值为0.67,表明两组参与者之间的实质性一致。这样,对于拒绝CVE条目,得到了六个主要类别,在下表中显示。
A.拒绝漏洞的类别
上表列出了拒绝原因的六个主要类别,及在收集的拒绝CVE中的对应分布。重复(Duplication)和通过进一步调查撤回(withdrawn by further investigation)是两个主要原因。在以下段落中讨论每个类别的详细信息。
重复:此类别指描述相同或漏洞重复的不同CVE条目。因为软件产品可能会在全球范围内传播,而独立的组织可能会面对并报告同样的漏洞。它将导致重复问题。某些重复很容易理解,但有时情况却很复杂。例如,CVE-2013-6405是CVE-2013-7263,CVE-2013-7264,CVE-2013-7265和CVE-2013-7281的副本。重复的CVE-2013-7263中有一个摘录:
其余三个CVE条目大约涉及三个不同的函数,分别为“ l2tp_ip recvmsg”,“ pn_recvmsg”,“ dgram_recvmsg”。它们都对名为“ recvfrom”,“ recvmmsg”,“ recvmsg”的三个系统调用具有潜在的危险,并且都与一定长度的值和不安全的内核堆栈内存有关。由于CVE-2013-6405也涉及这三个系统调用,因此被拒绝。
通过进一步调查撤回:此类别是指接受后经过进一步调查后被视为无效CVE。在此类别中,某些CVE在从“保留”状态移出之前被拒绝。有的首先被接受,然后在将来引起争议,最终被拒绝。真正的漏洞不仅需要由专家判断,而且还需要由行业从业人员进行验证。一些CVE条目被认为是漏洞,并且已为公众所了解,但最终无法发挥作用。以下注释显示了一个示例:
它显示了一种情况,其中最初将经过验证的行为误认为是软件缺陷,因为API是安全功能的形式。
错误识别:这一类是指不精确地提出的漏洞报告,这意味着对该CVE的描述最初结合了其他条目中存在的两个或多个独立问题。被拒绝的CVE CVE-2002-0192之一有以下评论:
它提供了一个示例,其中审阅者建议人们不要引用此错误标识的条目,而应引用其他适当的CVE条目。在数据集中,错误识别包含了7%的CVE。
缺乏详细信息:此类别是指缺少某些详细信息或使用歧义词的漏洞报告。结果,审阅者无法轻易理解该漏洞是什么。 CVE-2002-1918的说明如下:

可以看到,它使用两个“未知”来描述其漏洞。这些话非常模棱两可,因此可以被拒绝。 CVE提供的信息不能支持“潜在的远程攻击危险功能”是一个真正的漏洞的结论。
配置:此类别是指描述配置问题而非漏洞的CVE。覆盖通用配置枚举(CCE6)而不是CVE更合适。例如,CVE-2006-6967中提到了此问题。在此CVE中,提交者认为此漏洞将导致暴露“未指定敏感信息”。但由于以下原因而被拒绝:
审阅者确认,所报告的问题是配置错误,因此出于“配置”原因,所有与此类似的报告均被拒绝。
超出范围:此类是指CVE条目不描述漏洞,而是描述错误、设计缺陷或特征增强。 CVE被定义为众所周知的网络安全漏洞。它的边界很模糊,因此通常无法避免范围外的问题。一旦提交者无法确定CVE的范围,他们将把漏洞视为错误问题。一种情况来自CVE-2013-0743中的注释:权威人士评论说,关于SSL证书的问题不在CVE的范围内,并指出“不是被归类为CVE中的漏洞的问题”(not a problem that is categorized as a vulnerability within CVE)。因此,被此类评论拒绝的CVE被归类为“超出范围”。
其他:漏洞报告是由于其他原因而被拒绝的,例如,NVD的系统错误,丢失了导致拒绝的重要信息,或者某些记录已过时并由新提交者替代。因此,这些CVE的意义非常有限,将其分类为其他。
B.有争议的漏洞类别
上表列出了争议CVE条目的六个主要类别。无法复现是主要原因。
无法复现:此类别指的不能重现所报告的漏洞。有许多阻碍复制的障碍。为了更好地解释它,将给出一些示例。
第一个是CVE-2008-2956,它通过格式错误的XML描述了“内存泄漏”漏洞。但是,一位审阅者发现格式错误的XML几乎没有提供有用的信息,并说:“我永远无法确定发生问题的场景,而原始报告者也无法提供任何形式的复制细节。”(I was never able to identify a scenario under which a problem occurred and the original reporter wasn’t able to supply any sort of reproduction details.)这种重现失败是由于缺乏细节。
其次,即使某些阶段出现错误时即使信息足够,也会导致复现失败。在CVE-2007-2677中,提交者指出“多个PHP远程文件包含漏洞”(multiple PHP remote fifile inclusion vulnerabilities),而一个供应商则表示“由于代码是在函数中定义的,而该函数未从include / language.php中调用”(since the code is defined within a function that is not called from within includes/language.php)。在这种情况下,关键字“调用漏洞的函数”不起作用,因此该漏洞无法复制。
最后,在动态运行环境中存在一些漏洞,并且该漏洞只能以不稳定的方式进行复现,多次尝试才能成功。 CVE-2005-4486描述了“ SQL注入漏洞”。但是缺陷是部分隐藏的,部分是可见的,这意味着根本原因尚未明确。供应商对此表示异议,并说:“尽管可以通过使用产品来动态生成它们,但是对于news.asp不能重复。”
本身不是漏洞:此类别是指其中所报告的漏洞实际上受到保护或在其他相关产品中。
首先,某些CVE条目将声明一个过程不安全,而供应商指出该过程处于保护机制之下。与CVE-2008-6544一样,原始描述提供了“远程攻击漏洞”,而CVE和多个第三方对此问题提出了质疑,因为“文件包含针对直接请求的保护机制”。(the files contain a protection mechanism against direct request)
其次,一些报告的漏洞不是来自确定的产品,而是其他组件。其中一种情况发生在CVE-2006-1273中:根据报告,Mozilla Firefox的一个版本允许远程攻击者拒绝服务,然后触发崩溃。但是,由于它在“ IE Tab extension”中运行,并且“在Firefox本身中不是问题”,因此,审核人员对此表示怀疑。
不太严重的影响:此类别是指漏洞报告,其中报告的漏洞勉强地得到确认,但由于缺陷和后果还不够严重,因此仍存在争议。
一个例子是,据报告在CVE-2007-0253中,“grsecurity补丁”很容易受到攻击,但开发人员对此表示质疑,“他们声称存在此漏洞的函数是微不足道的函数,可以并且已经很容易地检查了任何假定的漏洞。”(the function they claim the vulnerability to be in is a trivial function, which can, and has been, easily checked for any supposed vulnerabilities)他们还引用了未经证实的过去披露。在此CVE条目中,该漏洞仅是一个微不足道的功能,不会影响整个产品。
另一个例子是在CVE-2007-0050中:报告了一个远程攻击漏洞,但供应商以及第三方发现“安装完成前的风险窗口很小”,因此他们对此表示怀疑。 “由于变量是在使用前设置的”,因此危害仅在很短的时间内出现,并且这种很小的风险窗口不太可能造成很大的影响。
误导:此类别是指漏洞报告误导了审阅者,甚至导致了争论和指责,而不是讨论漏洞本身。一个示例是CVE-2017-7397,该漏洞报告了“拒绝服务”漏洞。但是供应商对此表示争议,“已经证明此漏洞没有基础,并且完全是虚假的并且基于错误的假设。”(It has been proved that this vulnerability has no foundation and it is totally fake and based on false assumptions)争论者批评CVE提供了错误的信息。
CVE-2005-3497中的一个极端情况是出现了“ SQL注入漏洞”,但得到了供应商的强烈反对,即“这是100%错误的报告,这是来自存在漏洞的客户的诽谤。漏洞在他的服务器中,而不是软件中。”(this is 100% false reporting, this is a slander campaign from a customer who had a vulnerability in his SERVER, not the software)但是,后续调查表明原始报告是正确的。可以看到有时供应商会基于某些其他原因(例如声誉或利润)而不是基于事实来拒绝该漏洞。除此之外,当供应商认为提交者不可靠时,他们也会对此提出异议。
超出范围:与拒绝CVE中确定的类别相似,此类别中有争议的CVE指的不是描述漏洞而是错误,而是设计缺陷或功能增强的CVE条目。例如,在CVE-2017-8912和CVE-2006-7141中:
但是,CMS的供应商将CVE-2017-8912评为“一项功能,而不是错误”(A feature, not a bug)。审阅者评论说CVE-2006-7141并非“固有漏洞”。他们被认为超出安全边界,并涉及争议。
合法行为:此类别是指有争议的漏洞报告被认为是合法的并且受到完全控制。第一个示例是CVE-2014-5160中HP Data Protector中有关“单元请求服务”的目录遍历漏洞。但是,惠普供应商对此行为表示怀疑,这是“设计使然”。
第二个示例在CVE-2006-6165中进行了报告,该报告说,“有害环境变量”允许本地用户获得特权。但这与第三方有争议,指出“适当地清理环境是应用程序的责任。”(it is the responsibility of the application to properly sanitize the environment)在这种争论中,尽管确实存在遗留的潜在有害变量,但可以通过应用程序对其进行适当的清理,因此该行为也是合法的。
除此之外,某些报告的漏洞可能处于实际的业务逻辑之下。 CVE-2017-8769中的软件漏洞与商业道德之间的复杂争议之一是:

该CVE描述了一个操作,该操作将不删除源文件及其相应的聊天记录,但是“ Facebook Whatsapp”没有“将这些文件视为安全问题”,这是合理的,因为用户可能希望保留它,”无论其关联的聊天是否已删除”。在这种情况下,提交者认为用户隐私可能与软件漏洞密切相关,而供应商则认为这并不重要,这种价值差异也导致了争议。
其他:有的争议漏洞报告未提供争议的具体内容。他们中的大多数只是评论说供应商或可靠的第三方对此CVE提出异议。因此,这些CVE的细节尚不清楚,将其分类为其他。
0x05 无效CVE预测
上一节总结了对无效CVE的手动探索的实证研究。在本节中介绍了预测无效CVE的方法。
A.总体框架
上图展示了提出方法的总体框架。整个框架包括两个阶段:模型构建阶段和预测阶段。为避免获得后验信息,将评论和原始描述分开,并排除仅包含评论和评论的CVE条目。如下表所示,在清理数据之后,使用经过预处理的数据来构建模型。
对于每个CVE描述,框架都会对它们进行标记化,删除停用词(例如a,the),阻止它们(例如将它们还原为其根形式),然后以词袋的形式表示它们。
选择文本特征后,框架接下来将基于训练CVE数据的选定文本特征构造一个分类器。模型构建阶段将比较和有效/无效CVE的特征。在本文中研究了4种文本挖掘技术,即随机森林,SVM,朴素贝叶斯和多项式朴素贝叶斯。还将随机猜测分类器用作评判标准。
然后在预测阶段,使用分类器来预测未知的CVE是否有效。对于每个这样的CVE,框架首先对其进行预处理并提取文本特征,然后使用在模型构建阶段中选择的特征对其进行表示。接下来,在分类器应用步骤中将这些特征输入到分类器中。该步骤将输出预测结果,即有效或无效。
B.特征选择
先前的研究表明,特征选择技术可以提高文本分类的性能,使用信息增益(IG)来衡量预测标签所需的信息位数。将漏洞报告集合表示为:

其中Vn代表第n^t h个漏洞报告,In代表这是否无效,VRn中的项表示为:

计算信息增益(IG)。项t和标签i的信息增益得分计算为:
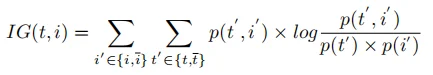
在应用特征选择来计算分数之后,将这些分数从高到低排序以生成排名列表。
C.评估指标
这些条目分别标记为“有效”和“无效”。如前所述,更关心的是异常情况,因此认为“无效”是肯定的。在这项研究中使用AUC来评估所提出的预测模型的有效性。选择AUC的原因如下:
1)常见的依赖阈值的度量(例如F1度量)通常依赖于概率阈值(例如0.5)来构建混淆矩阵,而AUC独立于该阈值。因此,使用AUC来避免阈值设置问题。一些研究人员还建议使用与阈值无关的度量(例如AUC),而不是诸如F1度量之类的与阈值无关的度量。
2)虽然AUC对不平衡数据不敏感,并且数据集不平衡,但AUC是更好的选择。与F1度量之类的其他度量相比,AUC在分类方面是更可靠的度量。使用其他度量(例如F1度量)在不平衡数据集中比较两个预测模型是不公平的。
3)AUC有清晰的统计解释。在方法中可以解释为,给定一对有效和无效的CVE,AUC将评估分类器对无效CVE的得分高于有效CVE的情况的概率。
D.实验结果
基于收集的CVE数据和提出的方法回答以下研究问题:
Q1:可以有效地预测无效的CVE吗?
动机:在目前的审查机制下,不可避免地会出现无效的CVE。想有效地预测CVE的新提交是否会涉及拒绝。因此使用数据库中CVE的原始文本内容,并应用不同的预测模型来研究建立有助于预测CVE有效性的准确模型是否可行。
方法:使用sci-kit学习工具来实现具有默认参数的预测模型,并使用标准模型(即随机猜测预测)来比较提出的预测模型。考虑到36,436种产品中CVE的多样性,为了提供整体见解,使用分层的10折交叉验证来评估模型的有效性。
在实验中,采用过采样技术来处理不平衡数据问题。此外使用相同的纵向数据设置来模拟,这意味着将CVE提交到数据库的时间顺序保持不变。根据时间顺序和5年间隔,将数据分为三部分(2002-2007、2008-2012、2013-2017)。依次地,使用前一折作为训练数据来预测下一折。 2002-2007年,2008-2012年和2013-2017年无效和有效报告的分布分别为509对28,309、155对26,138和122对39,706。
结果:上表分别给出了每种预测模型的10折交叉验证和时序验证的AUC结果。在10折交叉验证实验中,SVM达到了最佳性能,而随机森林排名第二。在时序实验中,随机森林取得了最佳性能,因为其所有AUC都比其他预测模型的AUC大得多。在10倍交叉验证中,随机森林和其他分类器的AUC之间没有统计学上的显着差异。考虑到这两个实验设置,随机森林模型的所有AUC均大于0.7,这表明性能良好。
此外,随机森林在时间序列验证方面具有最佳性能,它可以模拟实践中的用法。还使用误报率(FNR)来评估错误分类的风险。当将无效报告设置为肯定类别时,FNR表示有效至无效的错误分类率非常重要。所有模型的FNR均小于0.0001,表明分类错误的风险较低。因此,本方法可以有效地预测CVE是否为无效。
Q2:区分无效CVE和有效CVE的最重要特征是什么?
动机:由于训练数据是文本内容,因此特征以术语的频率表示,该术语频率与所有描述中术语出现的次数相对应。尽管有许多影响CVE无效的特征,但关注于寻找在何种程度上可以区分有效CVE和无效CVE的区分特征。
方法:基于文本内容,使用术语频率提取数千个文本特征。然后将信息增益用作每个特征的特征重要值,并根据信息增益对它们进行排序
结果:上表报告了根据其信息获取得分排序的前10个特征。注意到信息获取得分很低(可能的最高值为1),这表示在如此庞大的语料库中,仅一个特征不足以将有效CVE与无效CVE进行分类。请注意,“reject”不是标签,而是通常用于描述漏洞操作(例如“不拒绝负值”)。至于“ php”,无效CVE中与PHP相关的报告所占比例大于有效CVE和所有CVE中所占比例。 php文件是常见的攻击目标(参阅CVE-2005-4349)。
由于重复的CVE会导致拒绝,这表明有必要调查无效的漏洞报告,以免进行此类尝试(即浪费精力)。其他一些特征(例如““inclusion”,“allows”)是识别无效CVE的良好指标,因为根据经验研究,有时这类操作的描述不够具体,容易被拒绝或存在争议。
0x06 讨论
在实证研究中的类别给出了CVE变为无效、且预测模型实现预期性能的原因。基于这些结果讨论本研究的意义。
首先,重复和进一步调查撤回很容易导致拒绝。另外,在实践中,很难确定由于进一步调查而被撤回的被拒绝CVE。一个可能的原因是缺少有效的沟通渠道。因此,研究人员还应该研究如何在提交者和审阅者之间建立有效的沟通机制(例如,新的漏洞报告审阅系统),这将对漏洞检查和验证产生重大影响
其次,还发现复现失败会引发争议。漏洞报告一旦发布,将产生广泛的影响。这给CVE的权威性带来了一层含义,即仔细验证新提交的CVE非常重要。漏洞报告在完全复现之前不应该公开。在公开之前拒绝它比卷入争论要好得多。除此之外,根据无效漏洞类别,可以为新提交者创建指南以避免此类陷阱。
最后一点是,除了CVE数据库权限的努力外,提出的分类器还可以扩展以预测哪种CVE更有可能是无效的。尽管目前有很多保留的数据,但只要有足够的原始细节,本文数据驱动方法就可以在实践中发挥重要作用。无效漏洞对于研究很有价值,研究人员不应该忽略在CVE数据库或其他漏洞数据库中的无效漏洞报告数据。
0x07 结论与未来工作
本文关注了无效CVE,它将影响供应商,公司和用户的安全性、声誉和效率。首先贡献了无效的CVE数据集,研究人员将其忽略。然后进行了一项实证研究,对已拒绝和有争议的漏洞报告进行分类,并解释每个类别的详细信息。最后应用了几种预测模型来预测CVE是否会涉及无效状态,并且随机森林的最佳AUC大于0.87。将来,计划进一步提高工具的有效性。还计划试验来自更多安全平台的更多无效漏洞报告。
安全学术圈招募队友-ing,有兴趣加入学术圈的请联系secdr#qq.com
